
Introducing MAI-Voice-2
Today we’re launching MAI-Voice-2 — the most expressive, natural-sounding text-to-speech model we’ve built to date. It’s a significant leap from its predecessor across every dimension that matters to production voice experiences: fidelity, language coverage, speaker consistency, and emotional range. It is built for the products and services where voice quality directly impacts user experience: assistants or customer support that represent your brand, audiobooks that hold attention over hours, and accessibility experiences where voice is the only interface. It’s also built with responsible deployment in mind, with consent guardrails ensuring the technology is as trustworthy as it sounds. MAI-Voice-2 is now available in Microsoft Foundry, and is being integrated into VSCode and the Dynamics 365 Contact Center.
Features and capabilities
- Expanding from English‑only to 15 languages while maintaining the same naturalness and expressiveness as English.
- Granular emotion control via emotion tags: sad, whispered, excited, etc.
- Zero-shot voice prompting using 5-60s of reference audio available for all supported languages, with built-in consent guardrails.
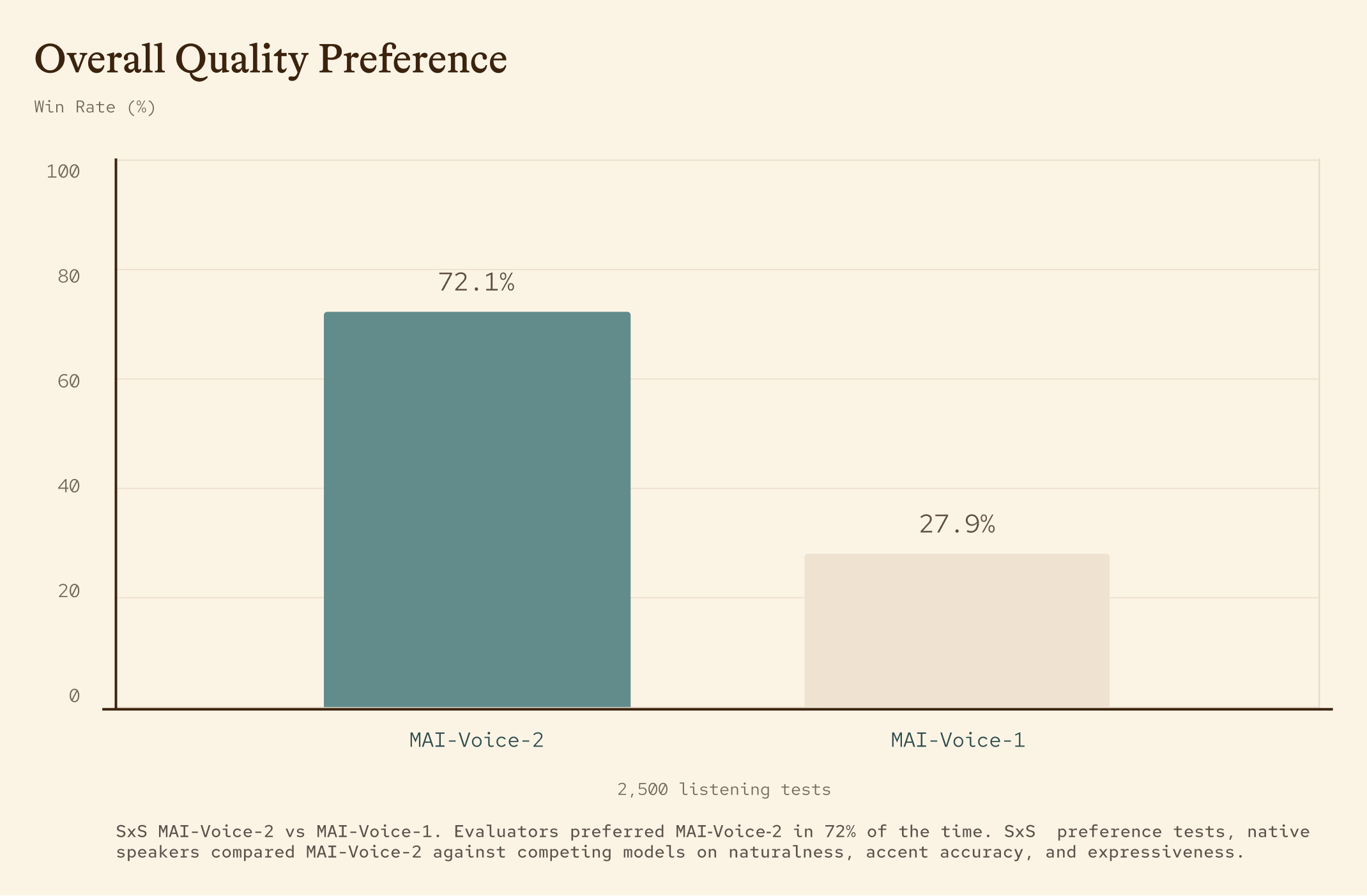
- MAI-Voice-2 is preferred over its predecessor MAI-Voice-1 72% of the time.
- Stable speaker identity across long-form content – audiobooks, podcasts, lectures.
- Code-switching capabilities for select language pairs — such as Hindi-English and Spanish-English — matching the way users naturally mix languages in everyday speech.
Hear it for yourself:
English (emotion: Embarrassed)
German (emotion: Confused)
Hindi (emotion: Excited)
English (role: Motivational Trainer)
English (role: Sports Commentator)
Performance
MAI-Voice-2 generates very natural speech in a controllable way. In side-by-side preference tests, it was preferred over its predecessors 72% of the time. In speaker similarity evaluations, speech generated by MAI-Voice-2 is indistinguishable from recordings of the same voice. Below, you can verify this yourself by trying to identify where the human speech ends and the MAI-Voice-2 output begins.
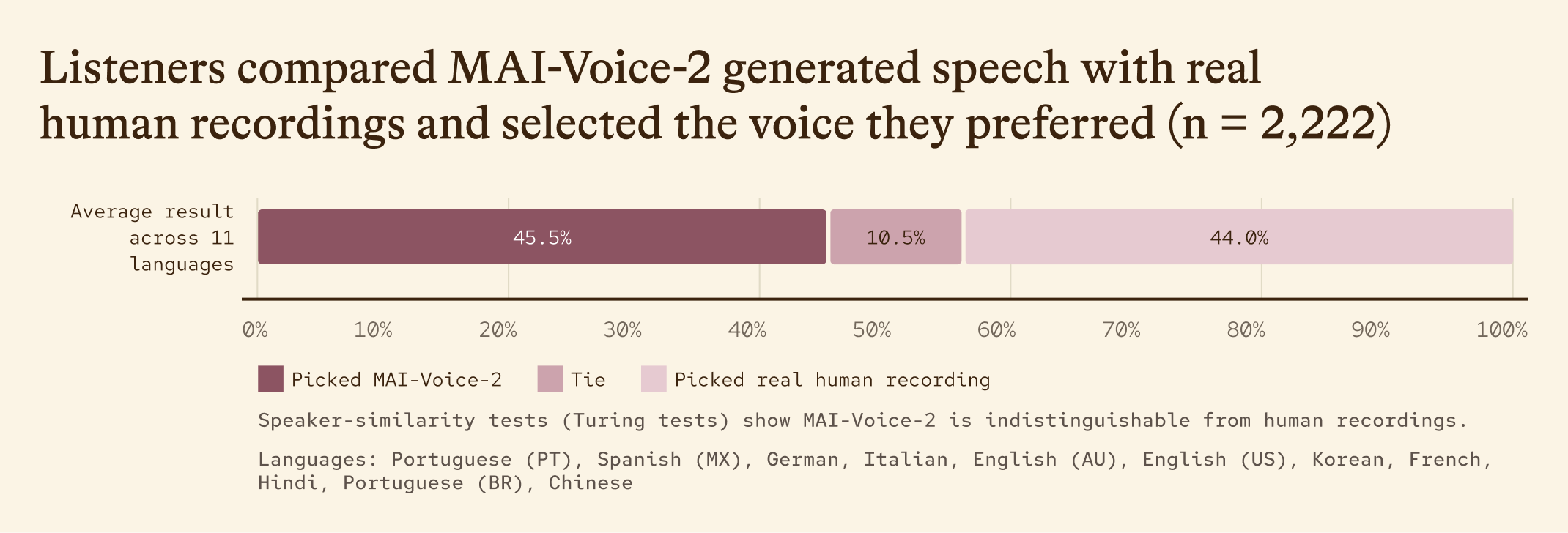
Guess the human recording vs. MAI‑Voice‑2
Listen to the audio clips below – each blends human recordings with speech generated by MAI‑Voice‑2. Can you tell where the human voice ends and the synthetic voice begins, or vice versa? Or does it sound like one continuous voice?
Human recorded + TTS
Language: English US
Human recorded + TTS
Language: Hindi (India)
Human recorded + TTS
Language: Spanish (Mexico)
TTS + Human recorded
Language: French (France)
Human recorded + TTS
Language: German (Germany)
Supported Languages
We prioritized depth across 15 languages, ensuring for supported languages we support a spectrum of expressive capabilities spanning tonal, pitch accent, stress timed, and syllable timed systems. We plan to continue expanding and refining the expressive range for all supported languages.
MAI-Voice-2 now supports the following languages/locales: English (US), English (Australia), Italian, French, German, Hindi, Spanish (Spain), Spanish (Mexico), Portuguese (Brazil), Portuguese (Portugal), Korean, Chinese (Simplified), Turkish, Russian, Thai, Dutch, Romanian and Hungarian.
In markets where people naturally mix languages, we support code-switching – notably Hindi–English and Spanish–English – reflecting how people actually speak. In internal testing, the model switches languages mid sentence fluidly, without losing prosodic naturalness nor speaker identity.
Hindi + English
Spanish (Mexican) + English
Voice Synthesis
Developers can create a custom voice in Microsoft Foundry across all supported languages using just a short reference clip – no retraining or fine tuning required. With only a few seconds of audio (recommended: 5–60 seconds), MAI Voice 2 can generate high quality speech that matches the speaker’s identity, making it easy for companies to bring their own brand voice into products without maintaining a separate voice model.
Consent and Safety
Consent is enforced at the system level: only authorized, licensed voices can be synthesized in production. No unlicensed voice cloning is possible. To gain access to this feature apply here.
Use Cases
- Assistants: Branded voices for Copilot, apps, devices, customer support.
- Entertainment: Characters for games, podcasts, audiobooks, AR/VR.
- Accessibility: Narration for visually impaired users; voice for speech impairments.
- Education: Instructors and characters for courses and simulations.
- Creators: Turn text into audio with your own voice. No studio required.
Try it out
DuoAI
DuoAI is an experimental experience that gives you a direct way to try MAI‑Voice‑2, MAI‑Transcribe‑1.5, and MAI‑Image‑2.5 models in action – showcasing natural, fluid, expressive dialogue. In the demo, you can engage in a three‑way conversation with two agents and even generate images using MAI‑Image‑2.5. It’s a practical preview of how MAI multimodal models work together to build powerful, customizable voice agents. Try DuoAI now
Note: DuoAI is not meant to showcase the capabilities of the underlying LLM – that component is modular and can be swapped as needed.
You can also explore the models directly in the MAI Playground.
Learn more about MAI-Voice-2
Build the Future With Us
We’re a lean, fast-moving lab made up of some of the world’s most talented minds. We have an exciting roadmap of compute at MAI, with our next-generation GB200 cluster now operational. And we have an ambitious mission we truly believe in. We’re also fortunate to partner with incredible product teams giving our models the chance to reach billions of users and create immense positive impact. If you’re a brilliant, highly-ambitious and low ego individual, you’ll fit right in—come and join us as we work on our next generation of models!


